Deploying Solar with BentoML
April 18, 2024 • This is a joint blog post written by:
- Sherlock Xu, Content Strategy at BentoML
- YoungHoon Jeon, Technical Writer at Upstage
Solar is an advanced large language model (LLM) developed by Upstage, a fast-growing AI startup specializing in providing full-stack LLM solutions for enterprise customers in the US, Korea and Asia. The company uses its advanced architecture and training techniques to develop the Solar foundation model, which is optimized for developing custom, purpose-trained LLMs for enterprises in public, private cloud, on-premise, and on-device environments.
In particular, one of its open-sourced models, Solar 10.7B, has gathered significant attention from the developer community since its release in December 2023. Despite its compact size, the model is remarkably powerful, even when compared with larger-size models beyond 30B parameters. This makes Solar an attractive option for users who want to optimize for speed and cost efficiency without sacrificing performance.
In this blog post, we will talk about how to deploy an LLM server powered by Solar and BentoML.
Before you begin
We suggest you set up a virtual environment for your project to keep your dependencies organized:
python -m venv solar-bentoml source solar-bentoml/bin/activate
Clone the project repo and install all the dependencies.
git clone https://github.com/bentoml/BentoVLLM.git cd BentoVLLM/solar-10.7b-instruct pip install -r requirements.txt && pip install -f -U "pydantic>=2.0"
Run the BentoML Service
The project you cloned contains a BentoML Service file service.py, which defines the serving logic of the Solar model. Let’s explore this file step by step.
It starts by importing necessary modules:
import uuid from typing import AsyncGenerator import bentoml from annotated_types import Ge, Le # Importing type annotations for input validation from typing_extensions import Annotated from bentovllm_openai.utils import openai_endpoints # Supporting OpenAI compatible endpoints
These imports are for asynchronous operations, type checking, the integration of BentoML, and an utility for supporting OpenAI-compatible endpoints. You will know more about them in the following sections.
Next, it specifies the model to use and gives it some guidelines to follow.
# Constants for controlling the model's behavior MAX_TOKENS = 1024 PROMPT_TEMPLATE = """### User: You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature. If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information. {user_prompt} ### Assistant: """ MODEL_ID = "upstage/SOLAR-10.7B-Instruct-v1.0"
Then, it defines a class-based BentoML Service (bentovllm-solar-instruct-service in this example) by using the @bentoml.service decorator. We specify that it should time out after 300 seconds and use one GPU of type nvidia-l4 on BentoCloud.
The @openai_endpoints decorator from bentovllm_openai.utils (available here) provides OpenAI-compatible endpoints (chat/completions and completions), allowing you to interact with it as if it were an OpenAI service itself.
@openai_endpoints(served_model=MODEL_ID) @bentoml.service( name="bentovllm-solar-instruct-service", traffic={ "timeout": 300, }, resources={ "gpu": 1, "gpu_type": "nvidia-l4", }, ) class VLLM: def __init__(self) -> None: from vllm import AsyncEngineArgs, AsyncLLMEngine # Configuring the engine with the model ID and other parameters ENGINE_ARGS = AsyncEngineArgs( model=MODEL_ID, max_model_len=MAX_TOKENS, gpu_memory_utilization=0.95 ) self.engine = AsyncLLMEngine.from_engine_args(ENGINE_ARGS)
Within the class, there is an LLM engine using vLLM as the backend option, which is a fast and easy-to-use open-source library for LLM inference and serving. The engine specifies the model and how many tokens it should generate.
Finally, we have an API method using @bentoml.api. It serves as the primary interface for processing input prompts and streaming back generated text.
class VLLM: def __init__(self) -> None: ... @bentoml.api async def generate( self, prompt: str = "Explain superconductors like I'm five years old", max_tokens: Annotated[int, Ge(128), Le(MAX_TOKENS)] = MAX_TOKENS, # Ensuring `max_tokens` falls within a specified range ) -> AsyncGenerator[str, None]: # Importing the SamplingParams class to specify how text generation is sampled from vllm import SamplingParams # Creating a SamplingParams object with the specified `max_tokens` SAMPLING_PARAM = SamplingParams(max_tokens=max_tokens) # Formatting the prompt to include the user's input in a predefined template prompt = PROMPT_TEMPLATE.format(user_prompt=prompt) # Adding a request to the engine for text generation stream = await self.engine.add_request(uuid.uuid4().hex, prompt, SAMPLING_PARAM) cursor = 0 # Iterating through the stream of generated text async for request_output in stream: text = request_output.outputs[0].text yield text[cursor:] cursor = len(text)
To run this project with bentoml serve, you need a NVIDIA GPU with at least 16G VRAM.
bentoml serve .
The server will be active at http://localhost:3000. You can communicate with it by using the curl command:
curl -X 'POST' \ 'http://localhost:3000/generate' \ -H 'accept: text/event-stream' \ -H 'Content-Type: application/json' \ -d '{ "prompt": "Explain superconductors like I am five years old", "max_tokens": 1024 }'

Alternatively, you can use OpenAI-compatible endpoints:
from openai import OpenAI client = OpenAI(base_url='http://localhost:3000/v1', api_key='na') chat_completion = client.chat.completions.create( model="upstage/Solar-10.7B-Instruct-v1.0", messages=[ { "role": "user", "content": "Explain superconductors like I'm five years old" } ], stream=True, ) for chunk in chat_completion: # Extract and print the content of the model's reply print(chunk.choices[0].delta.content or "", end="")
Deploy Solar to BentoCloud
Deploying LLMs in production often requires significant computational resources, particularly GPUs, which may not be available on local machines. Therefore, you can use BentoCloud, an AI Inference Platform for enterprise AI teams. It provides blazing fast auto-scaling and cold-start with fully-managed infrastructure for reliability and scalability.
Before you can deploy Solar to BentoCloud, you'll need to sign up and log in to BentoCloud.
With your BentoCloud account ready, navigate to the project's directory, then run:
bentoml deploy .
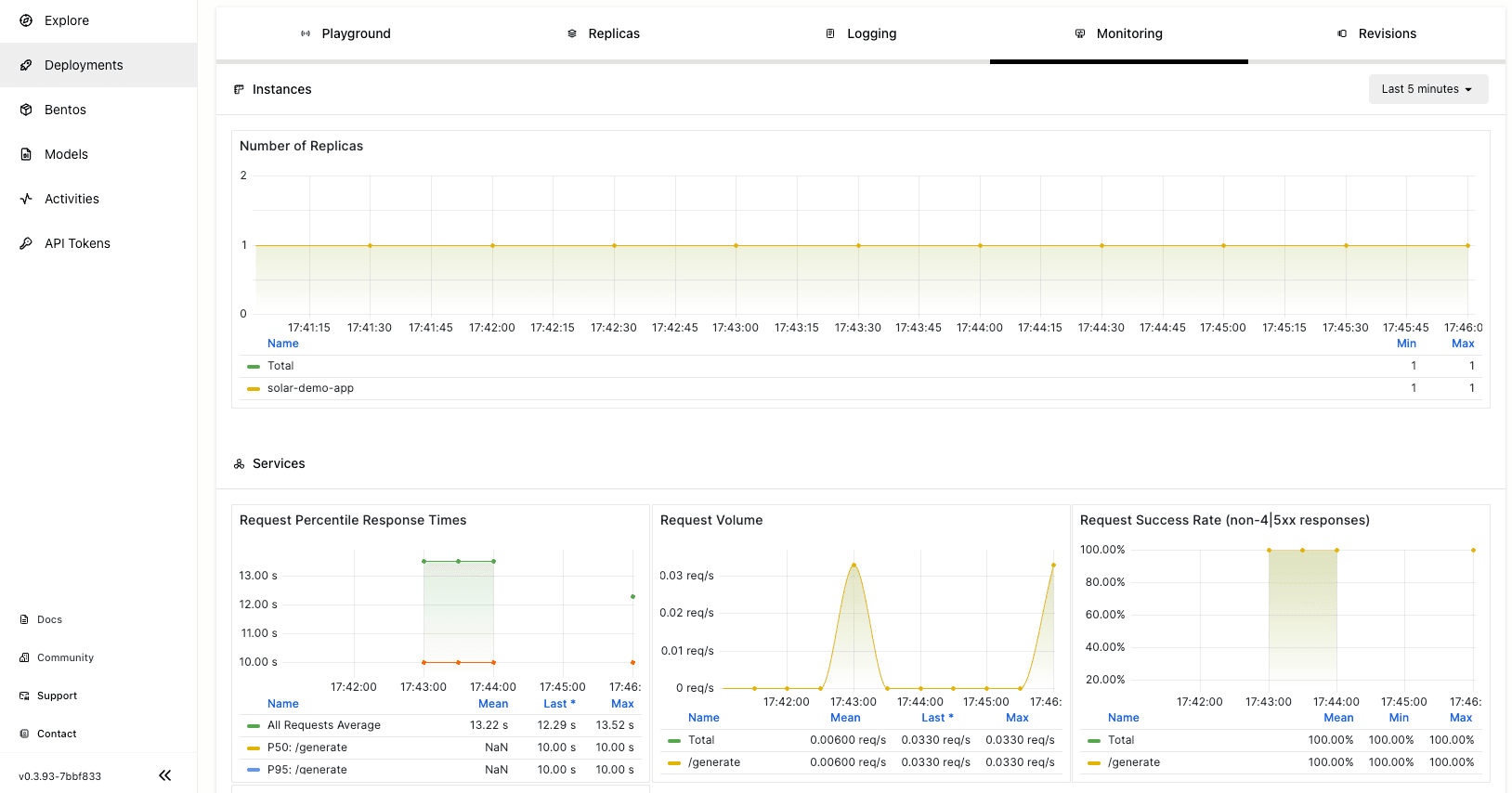
Once the deployment is complete, you can interact with it on the BentoCloud console:
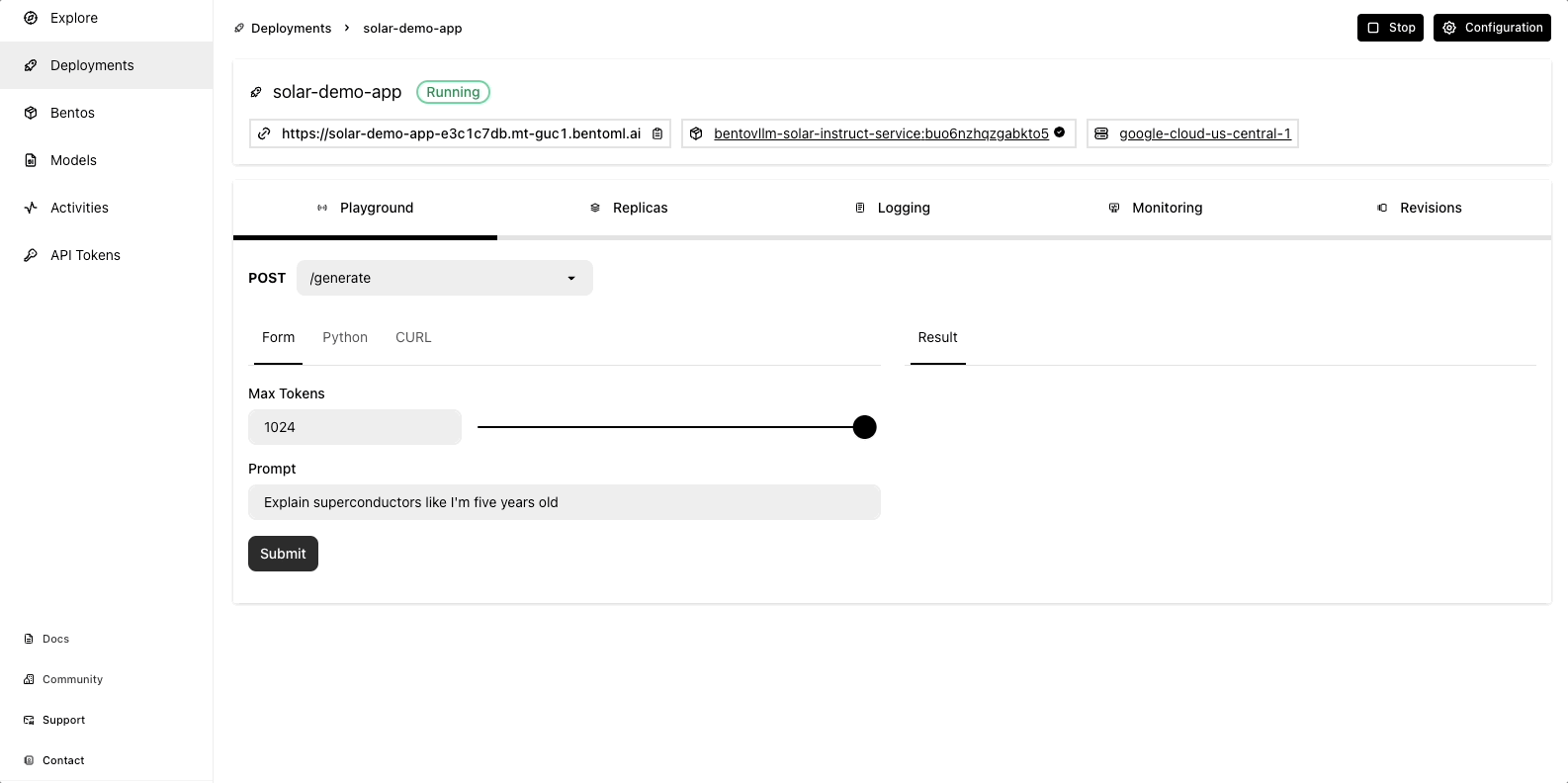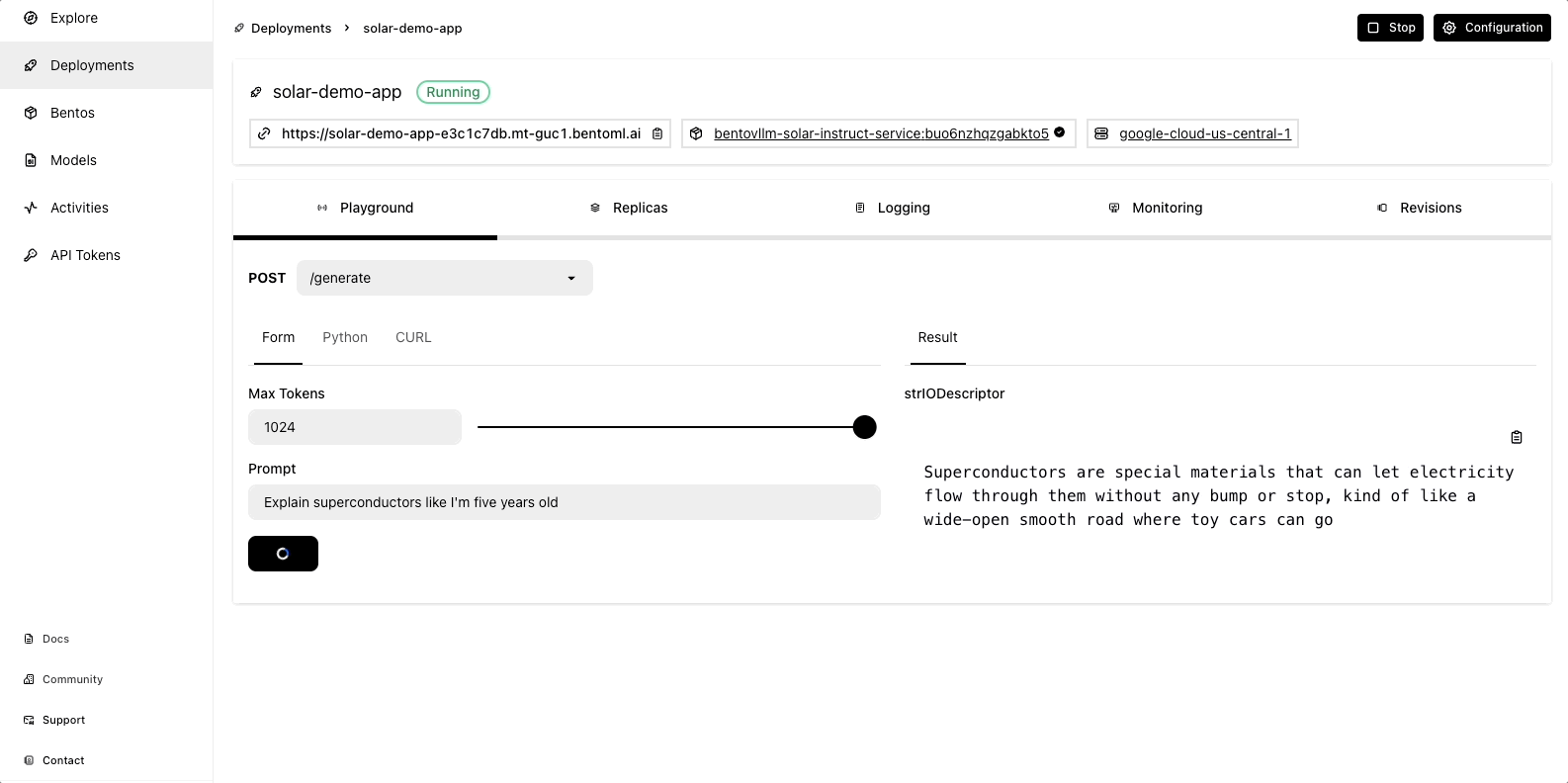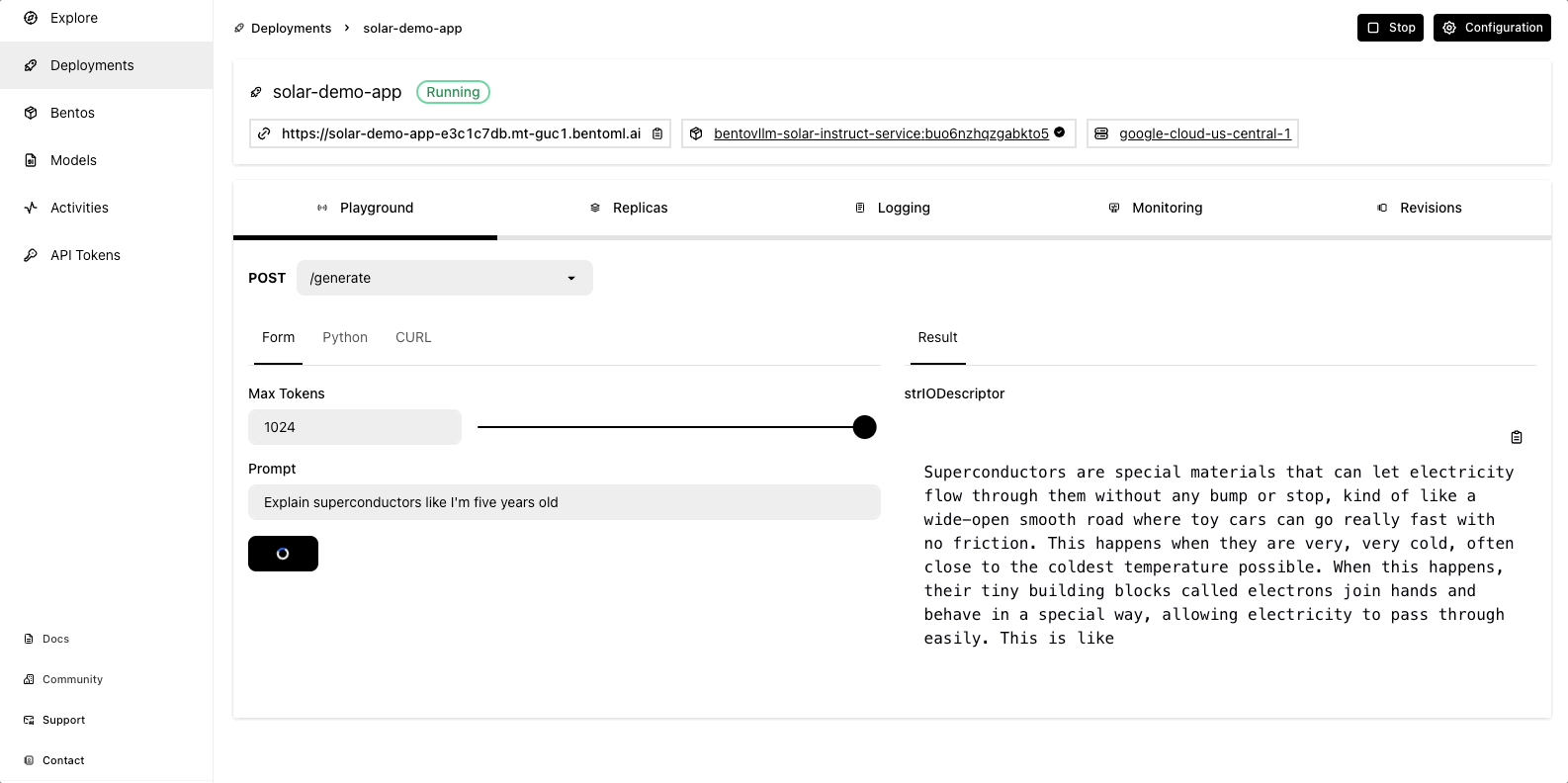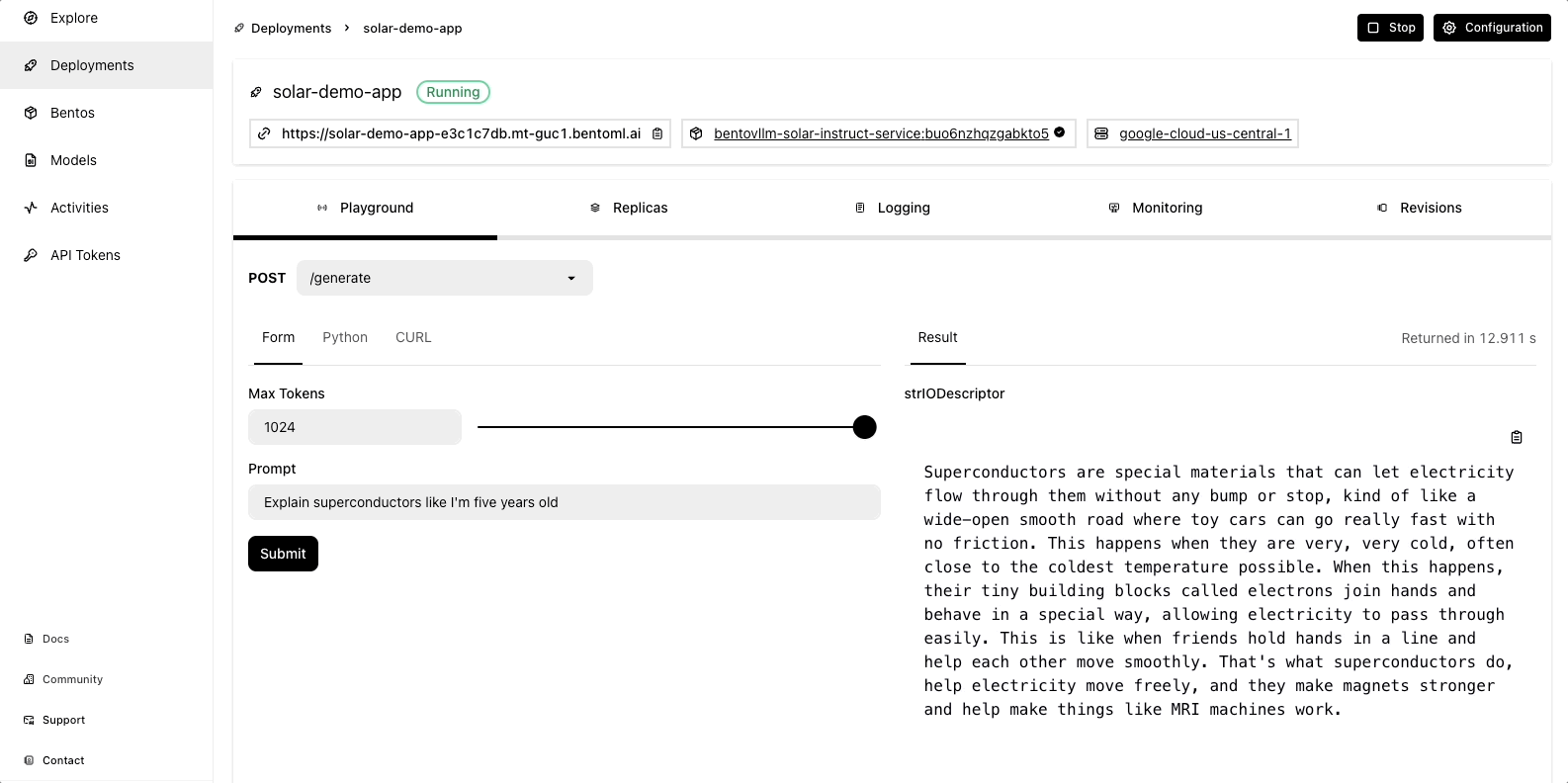
Observability metrics:
BentoML seamlessly integrates with a wide array of ML frameworks, simplifying the process of configuring environments across diverse in-house ML platforms. With its notable compatibility with leading frameworks such as Scikit-Learn, PyTorch, Tensorflow, Keras, FastAI, XGBoost, LightGBM, and CoreML, serving models becomes a breeze. Moreover, its multi-model functionality enables the amalgamation of results from models generated in different frameworks, catering to various business contexts or the backgrounds of model developers.
More on Solar and BentoML
To learn more about Solar by Upstage and BentoML, check out the following resources:
- Blog: Introducing Solar Mini with Performance Benchmark
- Research: Solar Depth Up-Scaling
- Blog: Using RAG with Solar
- Blog: Scaling AI Model Deployment
- BentoCloud is an AI Inference Platform for enterprise AI teams. Sign up now and get free credits!
- Join the BentoML Slack community to get help and contact us to schedule a call with our expert!